

Croyez-le ou non, tous les sites internet ont un facteur commun. C’est une chose primordiale qui doit être en place pour espérer apparaitre dans les SERPs des moteurs de recherche. Ce devrait être la première étape à effectuer après la conception du site lui-même. C’est quelque chose qui devrait être surveillé de près afin de s’assurer de recevoir un maximum de trafic provenant des recherches effectuées par les internautes. Assez de suspense ! La chose à laquelle je fais référence n’est nulle autre que : l’indexation. Il est nécessaire pour être reconnue en tant qu’entité au niveau de Google. Voici une courte description et des choses pratiques à savoir par rapport à ceci.
Qu’est qu’un index de site ?
 C’est comme une maquette de votre site du point de vue d’un engin de recherche. Il visite le site entièrement (en respectant les instructions de plusieurs facteurs) et prend en « note » chaque section. Il fait un dessin du site entier et se rappelle de chaque contenu/URL visité. Cette procédure a pour but de pouvoir présenter le contenu désiré aux internautes lorsqu’ils font une recherche sur les moteurs de recherche. Si le site wikipédia.org n’avait pas d’index, Google ne pourrait pas nous le présenter lors d’une recherche sur google.com. Ce qui fait que le premier résultat pour le mot-clé « France Wikipédia » est la page wikipédia qui parle de la France, c’est parce que Google a fait le tour du site wikipédia et qu’il a pris en note qu’une page en particulier parle de la France. Bien sûr, ce n’est pas seulement une question d’index. Il y a aussi tout un algorithme pour définir la pertinence de la page retournée lors d’une recherche. Le but utlime de Google est de présenter le contenu désiré à ses utilisateurs donc il prend en considération plus de 200 facteurs afin de déterminer quel est la meilleure page à présenter à l’individu. En gros, l’index est une carte mondiale de votre monde qu’est votre site web. Bien sûr, je répète, il y a plusieurs facteurs qui font que les crawlers des engins de recherche ne peuvent pas accéder à une certaine section d’un site, mais la banalisation que j’ai faite reste valide.
C’est comme une maquette de votre site du point de vue d’un engin de recherche. Il visite le site entièrement (en respectant les instructions de plusieurs facteurs) et prend en « note » chaque section. Il fait un dessin du site entier et se rappelle de chaque contenu/URL visité. Cette procédure a pour but de pouvoir présenter le contenu désiré aux internautes lorsqu’ils font une recherche sur les moteurs de recherche. Si le site wikipédia.org n’avait pas d’index, Google ne pourrait pas nous le présenter lors d’une recherche sur google.com. Ce qui fait que le premier résultat pour le mot-clé « France Wikipédia » est la page wikipédia qui parle de la France, c’est parce que Google a fait le tour du site wikipédia et qu’il a pris en note qu’une page en particulier parle de la France. Bien sûr, ce n’est pas seulement une question d’index. Il y a aussi tout un algorithme pour définir la pertinence de la page retournée lors d’une recherche. Le but utlime de Google est de présenter le contenu désiré à ses utilisateurs donc il prend en considération plus de 200 facteurs afin de déterminer quel est la meilleure page à présenter à l’individu. En gros, l’index est une carte mondiale de votre monde qu’est votre site web. Bien sûr, je répète, il y a plusieurs facteurs qui font que les crawlers des engins de recherche ne peuvent pas accéder à une certaine section d’un site, mais la banalisation que j’ai faite reste valide.
Vérifier les pages indexées sur Google
Il est bon de savoir quelles pages sont indexées sur Google pour pouvoir bloquer ceux qui sont indésirables ou ajouter ceux qui manque à l’index. Pour ce faire, sur le domaine google.com, faites la recherche suivante :
Site:ledomainedésiré.com
Voici une capture d’écran du résultat obtenu
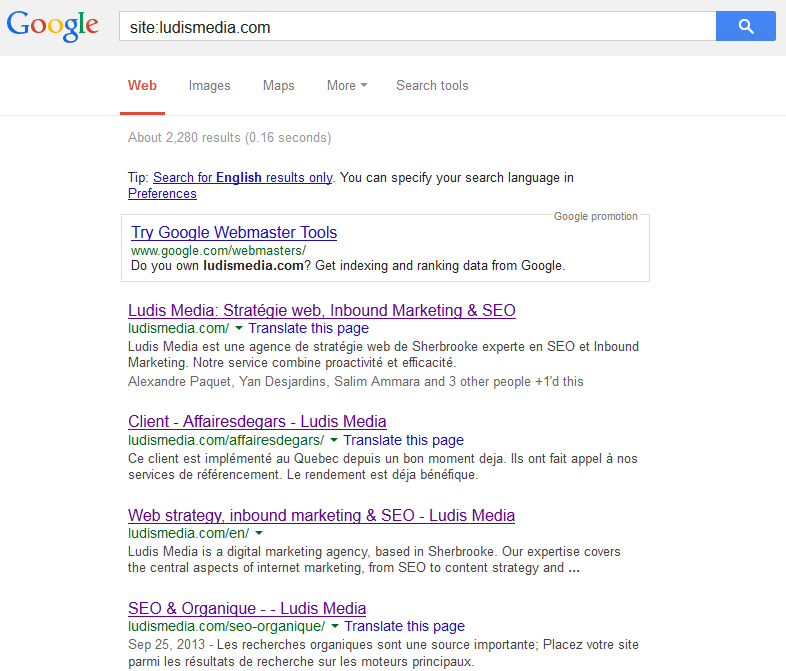
Cela vous donnera accès aux pages qui sont indexés pour le domaine désiré. Cette fonction marche aussi pour les moteurs de recherche populaires comme Bing, Yandex, etc…
Contrôler l’indexation de son site
Sitemap.xml
Pour aider les moteurs de recherche à bien indexer votre site, vous pouvez leur tracer vous-même une carte de votre site que vous rendez-vous disponible sur votre domaine. Ainsi, l’engin de recherche gardera en « tête » le plan de votre site tout en le « crawlant ». Voici à quoi ressemble un fichier « sitemap.xml » :

Robots.txt
Le fichier robot est un fichier texte qui permet de contrôler l’index de votre site en définissant des sections et si vous désirez les indexer. Si vous avez une section qui contient des informations personnelles d’utilisateur ( /user/* ), vous pouvez empêcher l’indexation de celle-ci. Voici à quoi ressemble le fichier pour un wordpress de base :

Metas tags Noindex
Ces tags peuvent être utilisés dans le header de certaines pages pour empêcher l’indexation de ceux-ci. Voici à quoi ressemble le tag :
<META NAME=”robots” CONTENT=”INDEX>
Cela peut être pratique pour empêcher l’indexation d’une page unique.
Google webmasters tools
Google a créé un outil pour avoir des informations concernant l’index de votre site : Google Webmasters Tool. Il vous permet aussi de contrôler certaines choses. Voici un aperçu de l’outil et des utilités qui s’y rattachent.
Index Status : Cette section vous permet de vérifier le nombre de page indexé, l’état de l’indexation, les pages bloqués par un robots.txt (j’en parlerai plus tard), les pages enlevées, etc… C’est toujours important de vérifier ces informations pour voir s’il y a des sections de votre site qui sont bloqués sans que vous le vouliez.
Remove URL : Si une URL avec des informations secrètes ou confidentielles se retrouvent indexée par Google et que ces informations ne devraient pas être accessible au public, il vous est possible d’utiliser un outil nommé Remove URL . Il vous permet de soumettre des URLs à désindexer sur le domaine de Google. Il serait bon de lire un tutoriel avant de l’utiliser puisque cet outil peut faire de grand dommage sur votre index de site. Voici ce qu’il faudrait lire avant de l’utiliser.
Les exemples et astuces présentés dans l’article se rattache beaucoup à Google puisque c’est le moteur de recherche #1 mais beaucoup de ces options sont disponibles sur les autres moteurs principaux. Il faut toujours garder en tête que l’index de votre site est à la base de votre visibilité et qu’il doit être contrôlé et géré avec précaution. Vos 3 meilleurs amis pour faciliter et contrôler l’indexation : sitemap.xml, robots.txt et Google webmasters Tools. Bon succès!
Latest posts by Alexandre Calderon
- Comment monter une campagne Adwords en moins de 2 heures - 24 Juillet 2014
- L’ABC de l’indexation - 4 Décembre 2013
- Une journée dans la vie d’un Stratège SEO - 7 Novembre 2013
- Google Adwords : Des Visites Payantes - 31 Octobre 2013
- Audit SEO : la pointe de l’iceberg - 9 Octobre 2013








Et oui, la base historique de l’hypertexte !
En effet 🙂 . C’est bon d’avoir un bon rappel sur les bases, et c’est bon de savoir comment bien contrôler ces bases pour bien être référencé. Je ferai une 2ème partie à cet article sur les façons d’embellir et d’enrichir le contenu de l’index au niveau de Google ( Authorship, review snippet, etc… ) . Merci pour votre commentaire et votre lecture, c’est apprécié 🙂
Je suis d’une autre génération et j’apprécie vos articles de vulgarisation. Continuez votre beau travail.